


Origin of Kubernetes
To understand the origin of Kubernetes we have to go back to when monolithic code was used extensively. In monolithic code, everything was written in a single file and deployed to the server as a single unit. All the application’s components, such as the UI, database access layers, and logic are combined into a single file and deployed as a single unit.
It was indeed easy to develop such kind of code but it has disadvantages like:
Complexity: Monolithic codebases can be challenging to maintain as an application expands and becomes more complicated. It might be tricky to make changes to the codebase without producing mistakes and it can be difficult to comprehend the overall structure and behavior of the application.
Difficulty Scaling: All the components are written in a single unit. When scaling a particular component, it might affect other components also. The components are dependent on each other so the entire application must be scaled together.
Difficulty making changes: The components of a monolithic are dependent on each other. One small change made in one component can greatly influence the other component's performance, stability, and runtime. So we can say that it is difficult to make changes in monolithic codebases.
However, to solve the problem of monolithic codebases the concept of microservices was introduced.
In microservices, all the components/services are developed independently. Each one of the services is responsible for a specific business logic. Each of the services can not only be developed independently but can be maintained independently also. Now the complexity, difficulty scaling, and difficulty in making changes are solved by the microservices architecture as the services are being developed independently as mentioned. The services are more stable and it allows the services to be fault tolerant which is one of many advantages of microservices.
With the advent of the architecture of microservices, the containerized application is used extensively to provide a consistent, portable environment for running microservices. Containers allow developers to package up an application and its dependencies into a single, lightweight package that can be easily deployed and run on any infrastructure.
The containers are nowadays mostly used for microservices and the demand for them is still increasing in recent years. The increase in the use of containers and containerized applications at a great scale is the key to the development of tools like Kubernetes, which is used to manage containerized applications at a scale.
So Now what is Kubernetes?
Kubernetes(also known as “K8s”) is an open-source container management tool that automates container deployment, scaling, and load balancing. It schedules, runs and manages isolated containers that are running on virtual/physical cloud machines. Kubernetes is also known as an orchestration tool. Orchestration is the process of managing the interactions between different components or systems to achieve the desired goal.
To understand Kubernetes, we have to understand what the containers do not do on their own.
We have to understand the problems with scaling up the containers.
Containers cannot communicate with each other
Autoscaling and load balancing was not possible
Containers had to be managed carefully.
Now we have already got a hint of what Kubernetes do. Let’s discuss some of the features of Kubernetes as well.
Orchestration
Autoscaling (Both vertical and horizontal)
Auto-Healing
Load Balancing
Platform Independent (Can be run on cloud/ virtual/physical)
Fault tolerance (Node /pod failure)
Rollback (Going back to the previous version)
Health monitoring of containers
Batch Execution
Supports JSON and YAML
Kubernetes Architecture
The Kubernetes architecture consists of mainly two parts:
Master Node
Working Node
The core components of master nodes are:
API Server
Kube Scheduler
Controller Manager
Etcd Cluster
The core components of the Worker Node are:
Kube-Proxy
Kubelet
Container Engine
Pod
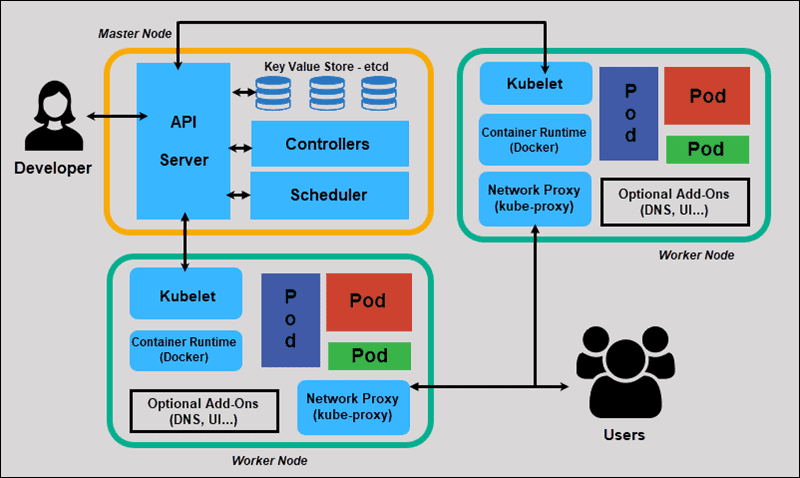
Now let us discuss the master node and its components in detail:
Master Node
The master node in Kubernetes is the main control plane for the cluster. It runs a set of k8s processes. These processes will ensure the smooth functioning of the cluster. These processes are called the ‘control plane’.
The main responsibility of the master nodes includes the:
Maintaining the state of the cluster: It makes sure that the cluster is in the desired state, as defined in the manifests file and the resources that have been applied to it. It makes sure that the application is running on the desired node, and action to bring the cluster into the desired state.
It constantly monitors the health of the cluster and its nodes and takes appropriate action if any problems are detected.
The rolling out of new versions is carried out by the master node only.
Based on the available resources, the master node also schedules workloads across the cluster.
Components
Kube-API Server
The cube API server is the hub of communication in Kubernetes. It interacts directly with the user and other components in the worker node. It can also be addressed as the front end of the control plane. It exposes the Kubernetes API to the other components and external clients/users to access and manipulate the cluster. It is the main entry point for all the commands and interactions with the cluster. Processing requests, verifying them, and sending them to the proper component for handling are its responsibilities. The API server in Kubernetes acts as a web server and listens for HTTP requests. It uses an HTTP method like GET, POST, and DELETE to perform operations on the resources represented as JSON or YAML objects. Some of the tasks performed by the API server are to deploy and scale applications, view the current state of the cluster, manage and configure pods, nodes and other resources create and modify users and roles, etc.
Note that kube-api server runs on port 6443.
Etcd
The primary purpose of the etcd is to store the metadata and status of the cluster. It is a consistent and highly available store. It is the key-value store that stores the current state of the clusters, and their configuration. The state of the cluster and its configuration are stored in a hierarchical key-value store, which targets fast and efficient lookups and updates.
The etcd stores the configuration of the cluster and its resources, such as pods, nodes, and services, the current state of the cluster and its resources, and the history of the cluster and its resources, which includes past configurations and states. The feature of etcd is:
Fully replicated: The entire state is available on every node in the cluster.
Secure: It is secure as it implements automatic TLS with optional client certificate authentication.
Fast: It is extremely high-performance as it can handle over 100,000 writes per second and 1 million reads per second on a cluster of three nodes.
Note that the etcd runs on port 2379.
Kube-Scheduler
The Kubernetes component known as kube-schedluer is in charge of allocating pods to cluster nodes. It accomplishes this by comparing the resource needs of the pods with the resource available on each node and then choosing the best node for the pod to run on.
To make sure that the pods in the cluster are effectively scheduled and running on the available best nodes, the kube-scheduler plays a crucial part. This enhances the cluster’s general performance and resource utilization.
The kube-scheduler plays a critical role in the operation of a Kubernetes cluster by helping to ensure that the pods in the cluster are efficiently and effectively scheduled and placed on the most appropriate nodes.
When a user requests the creation of and management of the pods, the kube-scheduler is going to take action on these requests. The kube-scheduler handles pod creation and management. The scheduler gets the information for hardware configuration from configuration files and schedules the pods on nodes accordingly.
Note that the kube-scheduler runs on port 10251.
Control Manager
The control manager which is also a component of the Kubernetes control plane is responsible for managing the control loop for the cluster. It maintains the desired state of the cluster over time.
The control manager gathers information about the current state of the cluster from etcd through the help of the API server. It compares the current state of the cluster with the desired state, which the user or application specifies using the API server. The control manager creates a series of instructions to bring the cluster back into alignment with the desired state whenever there is a difference between the current state and desired state. Those series of instructions are sent to the Kube-schedulers or the kubelets which execute the instructions and make the necessary changes to bring the cluster into the desired state.
Note that the control manager runs on port 10252.
Working Node
The worker machine that runs one or more pods is called the worker node. The nodes are managed by the Kubernetes master node. The roles of the working nodes are:
Running pods: Nodes are in charge of managing the pods that the Kubernetes control plane has given them. This involves pulling the container images for the pods, starting the containers, and managing their lifecycle.
Reporting status: The main role of the nodes is to report the status and feedback to the control plane or the master node which includes information about the resources available on the nod and the status of the pods that are running on the node. The Control plane uses this information to make scheduling and resource allocation decisions.
Executing Commands: It also executes the commands sent by the control plane. It includes the tasks like starting or stopping the containers, rescheduling pods, or updating the configuration of pods.
Components:
Kubelet
The kubelet is the component that is running on the node/worker node in a cluster. It is responsible for managing the pods on the node. It manages the pods by retrieving the container image and communicating with the container engine for starting the containers, monitoring the status of the containers and taking action if a container fails or is unhealthy, reporting the status of the pods and nodes to the master node/control plane, scaling up or down the number of replicas of deployment and mounting volumes and configuring the containers in the pods to use them.
The kubelet constantly communicates with the control plane to receive instructions for
Creating, deleting, and managing the pods that are running on the node. It ensures that
the pods are running properly in the node and can access the resources needed for them. In general, the kubelet retrieves the necessary container images from a container registry and starts the containers in the pod using the container runtime. It also configures the networking for the pod, ensuring that the container in the pod can communicate with each other and with other components in the cluster.
Note that kubelet runs on port 10250.
Container Engine / Container Runtime
The container engine is one of the components of the node that is responsible for managing the lifecycle of the containers, including pulling the necessary container images and starting the stopping containers. It is used by the kubelet or we can say that it works with the kubelet to achieve what it needs. It also exposes the containers on ports specified in the manifest file(we will come to this later).
Generally, the kubelet retrieves the container images for new pods from a container image registry and passes them to the container engine to start the container in the pods.
Kube-proxy
The kube-proxy is the component of the node that is responsible for implementing a part of the Kubernetes networking node, which allows the pods to communicate with each other and with the outside world. It is also responsible for load balancing, and service discovery in which kube-proxy maintains a mapping between service names and the pods that provide those services. When a pod is created, the kube-proxy assigns an IP address to the pod. The IP address of the pod is accessible only within the cluster due to this the external clients cannot access the pods directly. This is where we use services to expose the pods to the outer world.
When a request from the client reaches the service virtual IP, the request is forwarded to one of the pods by using the rules that kube-proxy created. The role of kube-proxy is to update the iptables rules on each node of the cluster when the service is created/deleted or the endpoints are modified. The iptables rules for the services are created by kube-proxy.
Pod
The pods are the smallest unit in Kubernetes. It is a unit of deployment that consists of one or more containers. For example, a pod might contain a web server container and a database container that communicates with each other using localhost. It is one of the basic building blocks of the Kubernetes application and they run more than one container as a single logical entity.
Some important features of the pods are:
The life span of the pods is very small i.e the pods are short-lived. They are replaced frequently. The pods are replaced in case of the pod fails or is deleted.
The containers inside the pod do not have their own IP address, the containers share the same IP address and network namespace, which means they communicate with each other using localhost.
Pods are managed by the higher levels of abstractions like ReplicationControllers, Deployments, or StatefulSets.
The pods do not auto-heal or auto-scale and the pod does not restart by itself. So to solve those problems, we use a higher level of abstraction like Deployment, ReplicationController, etc.
Some important points to note about the pods are:
When a pod gets created, it is scheduled to run on a node in your cluster.
The pod remains on that node until the process is terminated, the pod object is deleted, the pod is evicted for lack of resources, or the node fails.
If a pod is scheduled to a node that fails, or if the scheduling operation itself fails, the pod is deleted.
If a node dies, the pods scheduled to that node are scheduled for deletion after a timeout period.
A given pod is node “rescheduled” to a new node, instead it will be replaced by an identical pod, with even the same name if desired, but with a new UID.
Volumes in a pod will exist as long as that pod exists, if that pod is deleted for any reason, the volume is also destroyed and created as new on a new pod.
A controller can create and manage multiple pods, handling replication, rollout, and providing self-healing capabilities.