


Configuration Management Tool
Configuration management is a method through which we automate admin tasks by converting code into infrastructure(infrastructure as a code).
Configuration: Each and every single detail of the machine, server, storage, etc which includes files, folders, groups, permissions, OS, software, and any resources you could think of.
Management: Delete, Update, Create, etc.
So configuration management tools are programs or software that help manage the configuration of any system. Configuration management is the way to configure multiple servers and the working settings of those servers without manually opening the system and installing the required packages to meet our needs.
Initially, there used to be a system administrator who was responsible for handling and managing multiple servers. As the number of servers increased, the number of system administrators also increased. Handling and configuring that many servers manually was not an easy task. So there was a need for some automation to handle and configure multiple servers and storage at the same time, which would eventually save lots of time. As a result, with the advent of configuration management tools, multiple systems could be managed concurrently.
There are two types of configuration management tools:
- Push Based
- Pull Based
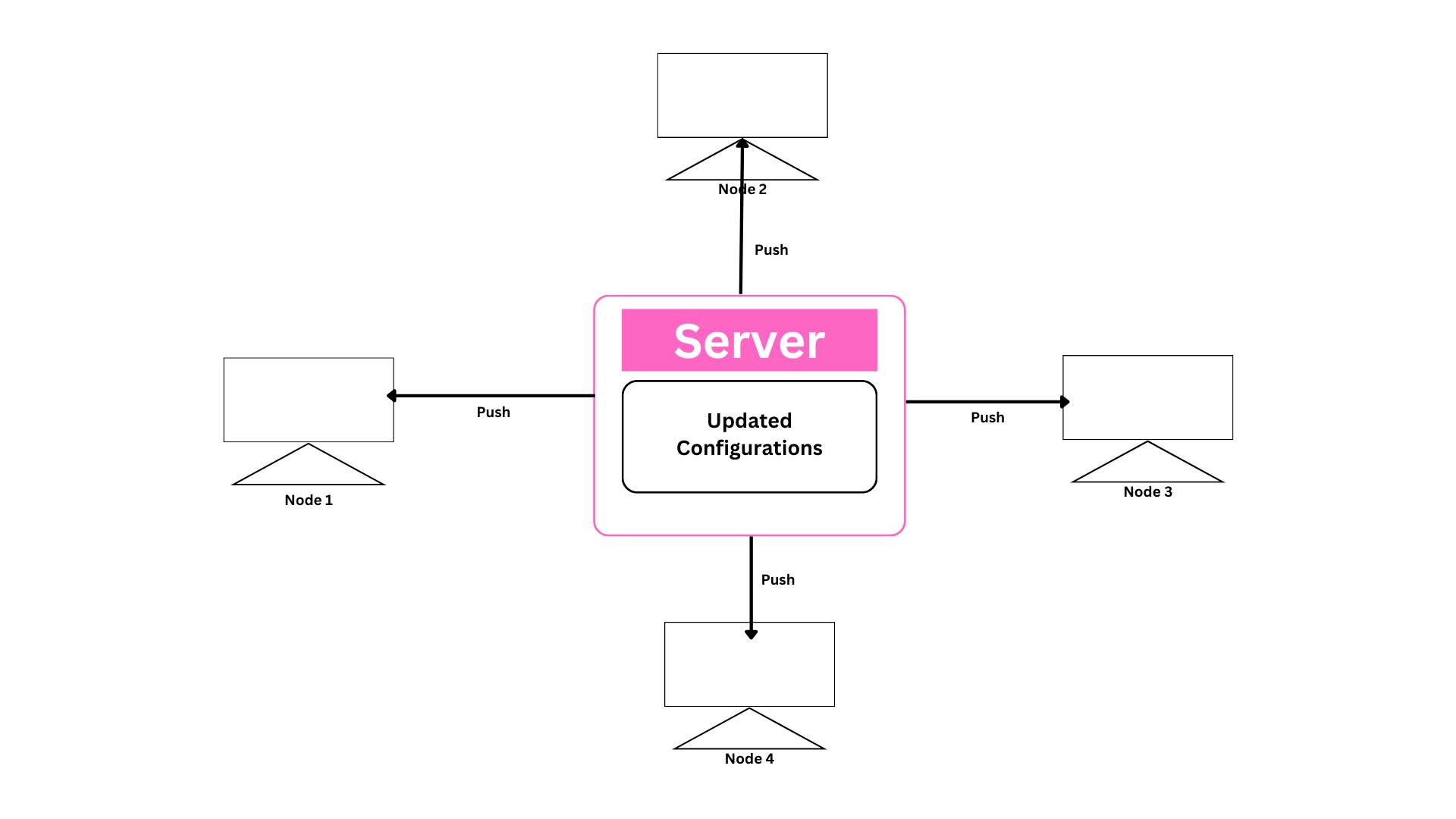
Push Based
In the push-based method, we have a central server that contains all the updated configurations for the nodes. We write the management code and store it on the server, and it automatically installs any files, software, or other updates that we want to make in the nodes that are connected to that server. At once, all the systems will be configured. So we create infrastructure with the help of code, which is known as infrastructure as code. It is mostly used when we want control over the server. When we want to make changes to the nodes, we save the updated configuration on the server and push it to each and every node.
Examples of Tools are:- Ansible, Saltstack, etc.
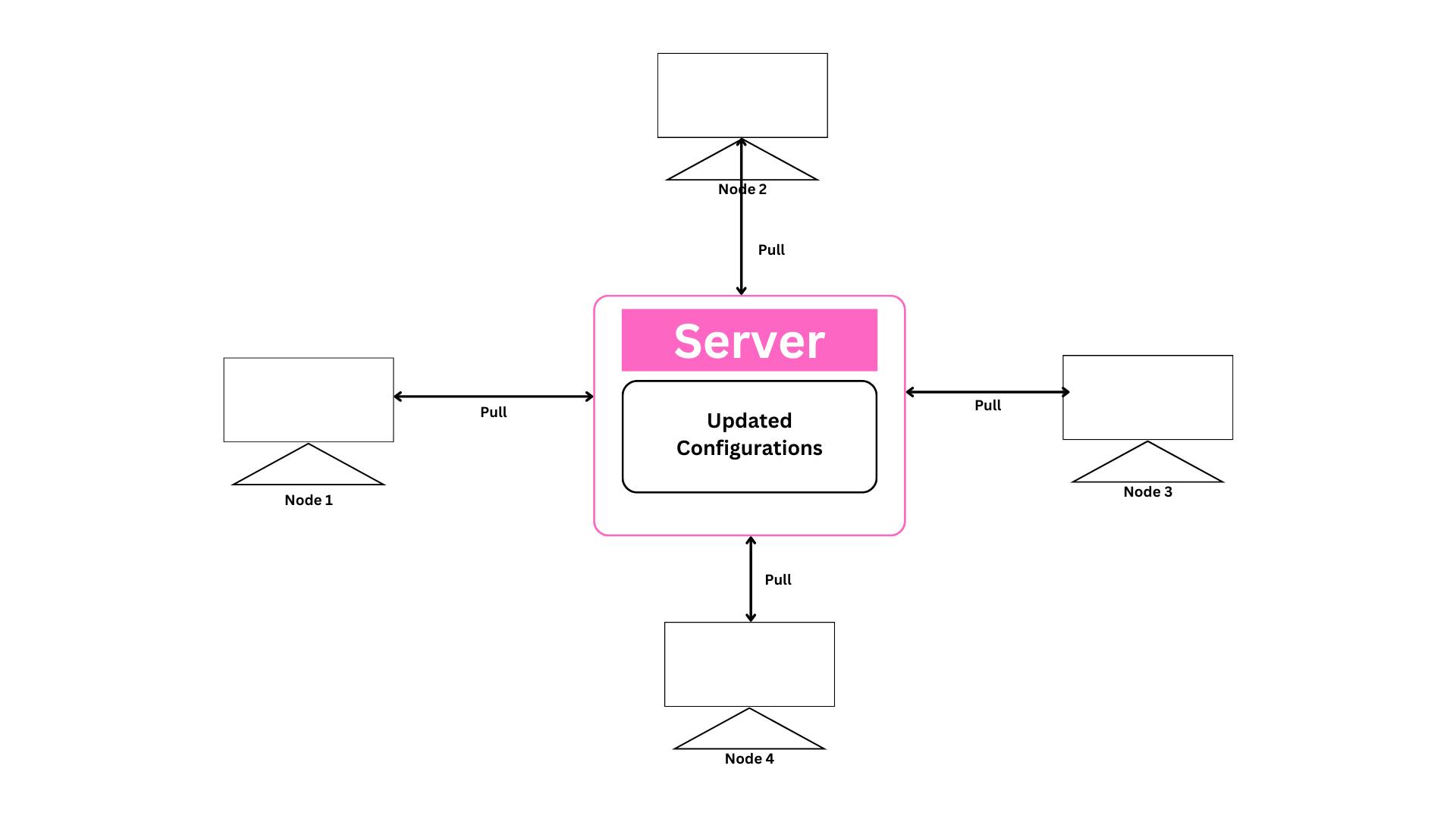
Pull Based
Similar to the push-based method, the pull-based method also has updated configurations on the server. In the pull-based method, the nodes check in with the server periodically, fetch the configuration from it, and update themselves.
Let us consider that we want to install git on the "n" number of servers that are connected to a pull-based server. So for installing git, we store the updated configuration, which basically contains the scripts, or let us consider some snippets of code that install git in the nodes. So now the node will keep checking the server for the configuration; when it finds one, it pulls the configuration and installs git on all the "n" servers. As soon as new nodes are connected to the server, it checks the files contained in itself and on the server. If there is a difference in files, then the node updates itself with the server files automatically.
Examples:- Chef, Puppet.
Chef
Chef is an open-source pull-based configuration management tool written in erlang and ruby. It is an automation tool. Whatever the system admin used to do manually, now we are automating all those tasks by using chef.
Chef Architecture
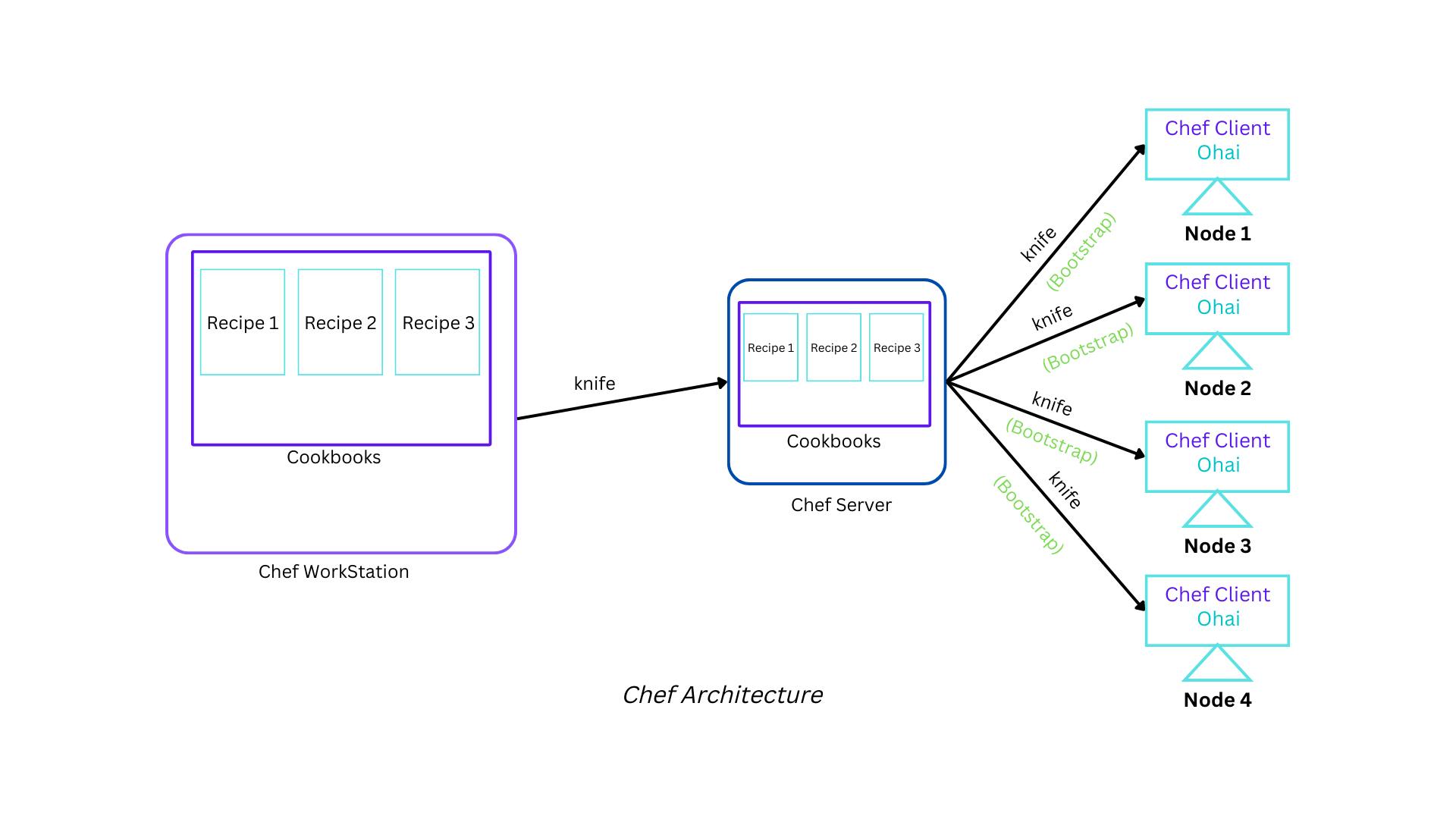
The Chef architecture consists of mainly 3 components: They are
- Chef Workstation
- Chef-Server
- Nodes
The infrastructure as a code, In other words, the infrastructure code is written at the Chef workstation. That code is also known as a recipe. There could be multiple recipes for doing multiple things. For example, to install Windows, we can use recipe 1, and to install Ubuntu, we can use recipe 2. The directory that contains all those recipes is known as a cookbook. So we can say that a cookbook is a collection of recipes. Although the cookbook and recipe are created on the workstation, they are stored on the Chef server and must be uploaded there. The CLI tool that helps us upload the cookbook from the workstation to the Chef server is known as a "knife." The same knife also helps connect the server with nodes, which is also called bootstrapping. We will discuss more about recipes, cookbooks, and knife later.
Coming to the Architecture. We have
Chef Workstations
They are the personal computers or virtual servers where all configuration code is created, tested, and changed. A DevOps engineer actually works here and writes code. This code is called a recipe. A collection of recipes is known as a cookbook. The workstation communicates with the chef server via a CLI tool called knife, which runs on the workstation.
Chef Server
The chef-server is a middleman between a workstation and the nodes. All the cookbooks are stored here. A chef-server may be hosted locally or remotely.
Node
Nodes are the systems that pull the updated configuration from the server at a certain interval of time to update themselves. These are the systems that require configuration. Ohai fetches the current state of the node where it’s located. The chef-client is used by Node to communicate with the chef-server. Each node can have a different configuration requirement. Chef-client is installed on every node.
Chef-client
As we mentioned earlier, the chef is a pull-based configuration management system. So the job of pulling is done by the chef-client that is located in each and every node. It gathers the current system configuration and downloads the desired configuration from the Chef server.
Ohai
Ohai's job is to keep the chef node's current state information up to date. It is also found in all the nodes. Ohai assists us in learning more about the nodes that are running our chef codes by using the "Node" object. Ohai provides information such as host details, IP address, node speed, and amount of memory text. Running the Ohai command on any node will return a JSON with all relevant information about the nodes. We will discuss more about ohai in detail.
Consider the following scenario: We have one node and want to configure Python on it. For this, we make a recipe and upload it to the chef server, and the nodes will pull the configuration and install it. Now we append more configuration to our recipe and again upload it to the chef server. As more configurations are added, the node will pull the recipe. Because we know our system already has Python installed, it will not reinstall Python. It will do the other configuration task. It is ensured that the changes will not apply repeatedly by tracking the state of the system resources. It is called idempotency.
We will cover a lot about Chef in upcoming blogs.